Japanese Font Support
 Or: The Least Critical-Path Feature I Could Have Possibly Spent a Day On
Or: The Least Critical-Path Feature I Could Have Possibly Spent a Day On
The General Plan
Localization has been on my mind a bit recently. It isn't part of the next milestone but I have always maintained a loose plan of action and so I sometimes revisit the idea to make sure I'm building the engine in such a way that translations will be simple to implement.
Most of the work to support other languages just has to do with text-replacement. There's text in-code, in-asset, and even, although rarely for this game, in-image that would all need run-time substitutes for other languages.
The vision for supporting this revolves around an asset-driven approach much like the rest of everything else in the game. Essentially, user-facing text will be a special object that understands the context it exists in but still is just a text box in the game's various asset UI's.
From there, we can collect all of them from all assets into a big spreadsheet with a different language in each column to define their replacements. This has a ton of benefits:
- Single source to work in and review remaining changes
- Live-updating game instance to see the changes in-context
- Sort search and edit across all assets and know their context at a glance
- Set of translations is a separate asset that can be applied or overridden the same as other assets
For hard-coded text in-engine, a macro is used to automatically register those strings with their own contexts to a core-generated part of the translation asset.
This won't be difficult to implement and should come together pretty quickly. Whoever gets contracted to do the localization should have a painless experience working in the game directly to get everything done!
As long as they only ever need 8x8 ASCII characters which should absolutely never be a problem!
The Problem
I don't know Japanese. But I have been around video games long enough to know that the further back in time you go, a problem that gets harder is rendering Japanese text.
My pseudo-fantasy-EGA engine is fully software-rasterized with every pixel of my 712x292 frame buffer being drawn on the CPU. Text is drawn by taking a font bitmap, grabbing a cached recolor of it for when you want different colors, and rendering it similar to a sprite atlas with the single-byte character code being an index into the grid. On the original EGA, these characters were baked into the hardware of the card and in cases of text modes you could only draw those characters on a pre-set text grid. The limits of my renderer are much more lax than that and I have some pretty generic freedom for where and how to draw text.
So when I started to think about supporting Japanese (or really any non-roman script) I thought ok, maybe I can just have a new font bitmap that has the new characters in the same 8x8 character resolution. If you just pull from the appropriate index in the (much) larger image it'll work the same as ASCII for all of the UI and content-responsive layouts and translators can just write Unicode into the translation tool.
The Misaki Font
After some googling (an increasingly rare way to start a sentence) I came upon this great Language Exchange comment talking about an 8x8 Kanji font. The responder pretty clearly says to not do this and also nicely adds some helpful screenshots and even talks about how fucking Dragon Quest on the 3DS had people unable to tell the difference between three different types of swords from the tiny text.
Never one to trust an expert opinion, I did not read any of that and hastily clicked the link of what not to use, bringing me, just as I assume many before me, to the Misaki font.

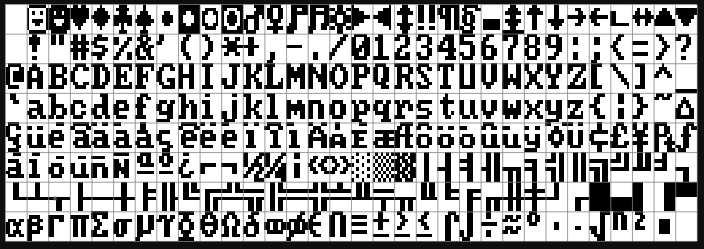
Chrome auto-translated the page which was helpful because I can't read any of it. Sorry, why was I doing this again? Oh right, localization. Skimming the page I saw that the font was created in the 90's for use with the Sharp PC-E500 Pocket Computer and also that the font was actually just 7x7 so it could have a single-pixel gap to make the characters not bleed together. I got the impression talking to others and seeing comments that most of these Kanji are just about impossible to discern on their own, requiring the context of the full sentence to infer.
Nevertheless, they had a PNG atlas to download the whole thing in one image, which is what I did for ASCII so I decided to start there!
A Quick Note on TTF
The website also makes a .TTF available, and using the incredible single-include library stb_truetype I could theoretically render the characters to a virtual bitmap and transfer those to the EGA framebuffer at runtime for text rendering. Applied to my other regular font-rendering this would open the door to variable font sizes and a lot of flexibility.
I played with this idea and even got a basic version working, but I was a little frustrated dialing in the precision for specific pixel sizes and getting the characters to render exactly the way I need them. I also think that the current text limitations are one of those creativity-producing limitations rather than one of those annoying limitations so I gave up on the idea.
So you have 8,836 Characters...
For ASCII there was just a nice 32x8 character grid and the unsigned char value of a character directly corresponded to an index in that 2D array. The Misaki font PNG was 94x94 with a ton of blank areas and both rhyme and reason to an organization that I had zero knowledge of.
I looked for documentation, text files that say what characters correspond to what grid positions, or even wondering if it was related to Unicode at all. Nothing. And it's not like I was going to try and figure out what characters were which to build it myself.
Feeling stumped at lunch, I vented my despair to @SP, Developer of Super Puzzled Cat, Launching January 2025 with a FREE DEMO you can play TODAY just in time for Steam Next Fest, and he half-remembered something about something called “Shift-JIS.”
This was the search term I needed, and I quickly found myself at the Wikipedia article for JIS X 0208, a two-byte Japanese Industrial Standard first written in 1978. The page is extremely helpful because it breaks down every “row” of characters in the 94x94 grid and I was able to confirm that it lined up perfectly with the Misaki font PNG. The way the encoding works is that to reference a character, you need it's kuten (区点) which refers to the two numbers, row-column, that act as cell coordinates in the 94x94 grid! Easy!
Mapping to Unicode
In the modern era, our main way to input non-ascii characters is with Unicode, assigning all characters 1-4 bytes as “codepoints” with encoding schemes for representing them in memory. I'm going to try hard not to get too into Unicode in the post because it will reveal how little I know about it.
Of course, following JIS X by over a decade, Unicode has exactly 0.000 correlation or overlap with JIS X. I'll repeat that for ascii we can just take the single-byte character from any string in C and index it into our little font map and be good. For Japanese Unicode codepoints from an asset file to correctly resolve to the correct kuten we were absolutely stumped without having a 1:1 map.
Luckily, Unicode has a website located somewhere deep beneath New York's Trinity Church hidden behind an elaborate series of thematic clues and puzzles. It contains a page with an ftp link to the older original JIS 0201 Mapping. I couldn't get the link to work but maybe I was FTPing wrong. (Update: Mastodon User @gamedevjeff was able to find the moved FTP link at ftp://ftp.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT)
Regardless, I really wanted 0208. On a lark I googled for the theoretical filename “JIS0208.TXT” and bingo! There, on Google's Github for their Japanese IME was the exact file I was looking for!
Written in 1990, the Unicode file contains 7000 lines of this:
0x8140 0x2121 0x3000 # IDEOGRAPHIC SPACE
0x8141 0x2122 0x3001 # IDEOGRAPHIC COMMA
0x8142 0x2123 0x3002 # IDEOGRAPHIC FULL STOP
0x8143 0x2124 0xFF0C # FULLWIDTH COMMA
0x8144 0x2125 0xFF0E # FULLWIDTH FULL STOP
0x8145 0x2126 0x30FB # KATAKANA MIDDLE DOT
0x8146 0x2127 0xFF1A # FULLWIDTH COLON
0x8147 0x2128 0xFF1B # FULLWIDTH SEMICOLON
0x8148 0x2129 0xFF1F # FULLWIDTH QUESTION MARK
0x8149 0x212A 0xFF01 # FULLWIDTH EXCLAMATION MARK
0x814A 0x212B 0x309B # KATAKANA-HIRAGANA VOICED SOUND MARK
0x814B 0x212C 0x309C # KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK
0x814C 0x212D 0x00B4 # ACUTE ACCENT
0x814D 0x212E 0xFF40 # FULLWIDTH GRAVE ACCENT
The first column is the Shift-JIS code (A modern extension of JIS), the second column is the JIS 0208 kuten and the 3rd is ✨The Unicode Codepoint✨
Writing a Parser
I should do a whole blog post about how I parse text these days, but about 5 years ago I stopped dreading file parsing forever when I started using “Accept-style” recursive-descent parsing. Whipping up a few lines to load this entire file into a hash-map at runtime only took a few minutes!
Here's the complete code, I've annotated it with a bunch of extra comments to explain what everything does.
// read 4 hex characters and shift the nibbles into a single 16-bit number
// returns true on success, populating out
static bool _acceptHexShort(StringParser& p, uint32_t* out) {
auto snap = p.pos; // error recovery snapshot
uint32_t workingNum = 0;
// 4 nibbles
for (int i = 0; i < 4; ++i) {
char d = 0;
if (!p.acceptAnyOf("0123456789ABCDEF", &d)) {
p.pos = snap;
return false;
}
// convert the char to a number
if (d >= 'A') d = d - 'A' + 10;
else d -= '0';
// shift it into place
workingNum |= d << ((3 - i) * 4);
}
*out = workingNum;
return true;
}
// contains the 3 numbers in a line of the map file
struct JISMapLine {
uint32_t shiftjis = 0, jis0208 = 0, unicode = 0;
};
static void _constructUnicodeToJISMap(sp::hash_map<uint32_t, Int2>& mapOut) {
auto file = bundledFileString("JIS0208.TXT"); // in-house file-bundler, the txt is encoded inside the exe and sitting in memory at this point
StringParser p = { file.c_str(), file.c_str() + file.size() };
while (!p.atEnd()) {
if (p.accept("0x")) {
// start of new line
JISMapLine line;
if (_acceptHexShort(p, &line.shiftjis) &&
p.accept("\t0x") && _acceptHexShort(p, &line.jis0208) &&
p.accept("\t0x") && _acceptHexShort(p, &line.unicode)) {
// we grabbed the 3 numbers, split the jis0208 into two nibbles
// the kuten start at 0x20 (32) and are 1-based
auto row = (int)(((line.jis0208 >> 8) & 0xFF) - 0x20);
auto col = (int)((line.jis0208 & 0xFF) - 0x20);
// map this 2d integer point to the unicode codepoint
mapOut.insert(line.unicode, Int2{ col - 1, row - 1 });
}
}
while (!p.atEnd() && !p.accept('\n')) p.skip(); // skip to end of line
}
}
Int2 JISCellFromUniChar(uint32_t unicode) {
static sp::hash_map<uint32_t, Int2> _Map; // in-house hashmap
if (_Map.empty()) {
// populate once per program run
_constructUnicodeToJISMap(_Map);
}
// this hashtable is way faster than std::unordered_map so this is fine
if (auto srch = _Map.find(unicode)) {
return *srch.value;
}
return { -1,-1 };
}
So We're Done! Almost...
With our shiny new JISCellFromUniChar function we can pass any codepoint up to 4-bytes and get a supported kuten for referencing a cell in our Misaki PNG.
But there is the tiny issue of getting those codepoints. Again, I'm not going to get into Unicode too much here but the main thing is that a utf8 string is still just a null-terminated const char* in your code but you can no longer just read it one byte at a time. Instead, every time you go to read a character, you can check specific bits to see if the character is continuing into the next byte. There are great small libraries for traversing a utf8 string but I had never written one before so here's mine...
const char* utf8ToCodepoint(const char* input, uint32_t* codepoint) {
auto s = (unsigned char*)input;
if (s[0] < 0x80) {
*codepoint = s[0];
return input + 1;
}
else if ((s[0] & 0xE0) == 0xC0) {
*codepoint = ((s[0] & 0x1F) << 6) | (s[1] & 0x3F);
return input + 2;
}
else if ((s[0] & 0xF0) == 0xE0) {
*codepoint = ((s[0] & 0x0F) << 12) | ((s[1] & 0x3F) << 6) | (s[2] & 0x3F);
return input + 3;
}
else if ((s[0] & 0xF8) == 0xF0) {
*codepoint = ((s[0] & 0x07) << 18) | ((s[1] & 0x3F) << 12) | ((s[2] & 0x3F) << 6) | (s[3] & 0x3F);
return input + 4;
}
*codepoint = 0xFFFD; // invalid
return input + 1;
}
Finally, it's time to actually render the characters. We traverse our utf8 string, pull out the codepoints, look up the kuten, and build a UV rect for the font texture:
void egaRenderTextSingleCharUnicode(EGATexture& target, EGATexture& font, Int2 pos, uint32_t codepoint, EGARegion* clipRect) {
codepoint = convertAsciiCodepointToFullWidth(codepoint);
auto cell = JISCellFromUniChar(codepoint);
if (cell.x >= 0 && cell.y >= 0) {
Recti uv = { cell.x * EGA_TEXT_CHAR_WIDTH, cell.y * EGA_TEXT_CHAR_HEIGHT, EGA_TEXT_CHAR_WIDTH, EGA_TEXT_CHAR_HEIGHT };
egaRenderTexturePartial(target, pos, font, uv, clipRect);
}
else {
// err
egaRenderLineRect(target, Recti::fromVecs(pos, Int2{ EGA_TEXT_CHAR_WIDTH, EGA_TEXT_CHAR_HEIGHT }).expand(-2, 0), EGAUIColor_ltred, clipRect);
}
}
void egaRenderTextUnicode(EGATexture& target, EGATexture& font, Int2 pos, const char* text_begin, const char* text_end, EGARegion* clipRect) {
if (!text_end) text_end = text_begin + strlen(text_begin);
auto cur = text_begin;
while (cur != text_end) {
uint32_t cp;
cur = utf8ToCodepoint(cur, &cp);
egaRenderTextSingleCharUnicode(target, font, pos, cp, clipRect);
pos.x += EGA_TEXT_CHAR_WIDTH;
}
}
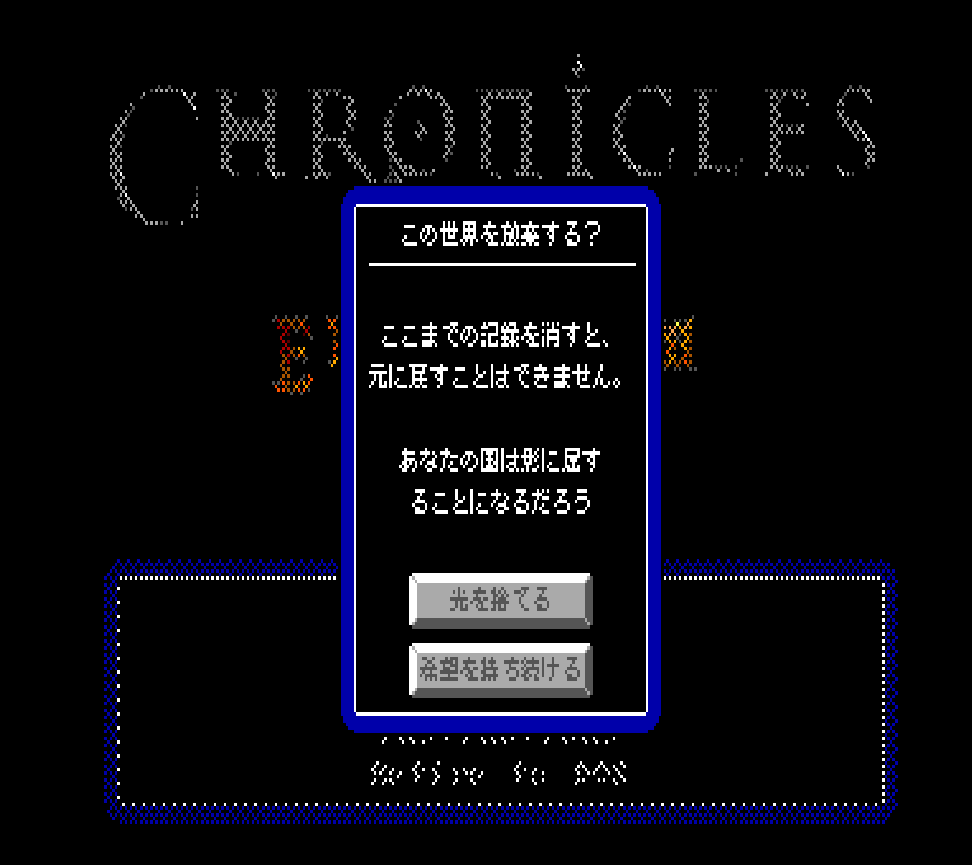
And then we let 'er rip and prayed! At this I had absolutely no way of knowing if the values inside the map were correct or garbage or what.
auto uniFont = egaFontFactoryGetFont(gi.state.fontFactory, EGAUIColor_black, EGAUIColor_white, EGAFontEncodingType_Unicode);
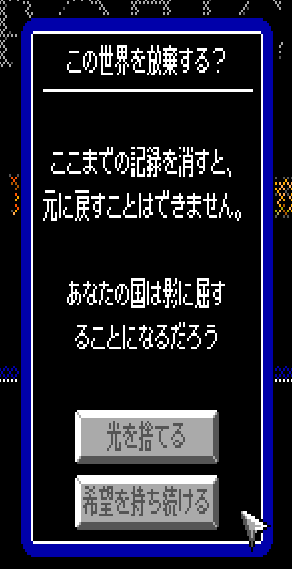
egaRenderTextUnicode(gi.ega, *uniFont, Int2{ 8,8 }, u8"あなたの国は影に屈することになるだろう");
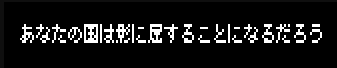
And it worked!
The folks at Nice Gear Games were nice enough to translate my overdramatic save-deletion dialog so that I could test it out:
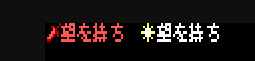
One great thing with this is that my rich-text rendering still works! So text color and inline icons are already perfect:
One Last Hang-up
The font also has roman characters, so I went ahead and tried to write a regular English message but none of the characters rendered. Well, sure enough, the codes represented by JIS are the Full-Width roman characters which have different codepoints than what ASCII maps to.
So yet another function for catching those full-width conversions:
uint32_t convertAsciiCodepointToFullWidth(uint32_t c) {
if (c == ' ') {
c = 0x3000;
}
else if (c >= '!' && c <= '~') {
c += 0xFEE0;
}
return c;
}
Maybe That Person Was Right About 8x8
After the excitement of getting this all working wore off I did start to notice/hear that the text is very hard to read. The Misaki font page does have an 8x12 font that is more readable so I went ahead and tried tossing that into the game. Now, this one's a bit more involved because the 8x8 font size is hard-coded and so changing it for this messes up a lot of things. I would be a bit more work to actually update the UI to support variable-height text. But I'm happy to show that the larger font size works just fine with the content-response UI in the game and looks really slick:
Thank You For Reading!
I really wrote a lot here but this was such a fun little project to get sniped by! As always, if you'd like to reach out or discuss the content here, you can reach out to me on Mastodon or else reply to the post about this post which I'll link here. Have a great day!!
Now all I need to do is finish making the game so that somebody can translate it someday!
 Wishlist Chronicles IV: Ebonheim!
Wishlist Chronicles IV: Ebonheim!