Dungeon Puzzle Sweeper
Happy new year! It's 2026, this blog was quiet last year, and I released a video game last month, so let's talk!
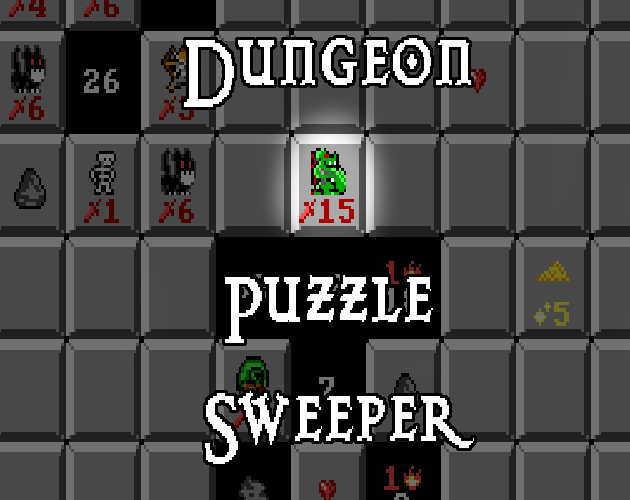
It's been 3 weeks since the the official itch.io launch of Dungeon Puzzle Sweeper! This has by far been my most visible and successful game launch on itch which was very new for me, so I wanted to do a little debriefing about the development of the project and post-launch statistics!
Development
My last mention of this project was last June when I had already moved on from it. I had built out the game and had it running on the web browser hosted on my own site but it was incomplete, needing some new art assets, and I was itching to get back to Chronicles so I shelved it for the rest of the year.
How it started was that I was obsessed with Daniel Benmergui's Dragonsweeper and it being very UI-based it caught my eye as something I could probably build using the Chronicles EGAUI system. I'm at least a little bit of a minesweeper weirdo and so I got a prototype working in an evening
Generating the Board
The Dragonsweeper board has a lot of rules that determine how the board gets generated. Learning these is part of the game so spoilers ahead!
Click here for Drasgonsweeper spoilers
The lich always spawns in a corner, the slime mage always spawns surrounded by 8's on an edge, the dragon of course spawns in the center, gargoyles spawn in pairs facing each other. Additionally, in v1, one of the two vision orbs always spawned with 1 heart nearby, and there's a lot of rules to try and ensure certain characters don't spawn next to each other.
The first way one would think to implement this is to just loop over all your stuff that you want to add to the board and, for each one, search the board for all the possible spots it's allowed to spawn in and pick one randomly. This works but has problems.
The big issue here to me is computational complexity, which even for a simple game, caused the board generation to take up to 1 second. The reason for this is that every unit being placed needs to iterate over every currently-placed unit to determine their placement rules in relation to the unit you're processing, which in turn iterates over all placed units related to it, etc. You quickly hit N^2 on this.
The other problem is that depending on the complexity of the rules and how many free squares you get, it's not hard to generate a partial board where the rest of the units can't be placed. You might try to shuffle existing ones around to make the rest of the units fit, but depending on implementation you're either going to create an unreliable board that doesn't have all the units every time or you're going to be throwing away gens and retrying a fair amount.
Dragonsweeper v1 had (has?) these issues, even so far as the possible final 100% score not being reliable due to possible generation bugs.
Now, I don't think this slows that game down in the least, it's an exceptionally good and fun video game, but it did get my brain on the kick of trying to improve the generation.
Waveform Collapse
This very trendy and cool sounding thing is popular around procgen enthusiasts and used in a lot of great projects. I'm a novice at all of that but to me it more or less came down to propagating restraints.
The gist of the algorithm is that, given a series of events, which all have constraints for occurring:
- Execute the event with the most constraints
- Reevaluate the constraints of the remaining events
- Repeat until all events have occurred
By always executing the most-constrained event first, its possibility space is maximized, and the interrelated constraints (A depends on B occurring first, B's possibility of occurring relies on how A occurred, etc) which potentially constrain future events propagate downwards. This aims to ensure that the least-permissive events are allowed to occur while the most-permissive events don't clog the space.
The way I applied this theory to dragonsweeper is such:
- Every tile that will be placed has a set of possible tiles it can be spawned in.
- Each tile type has a lambda for generating the initial set (dragon only has 1, lich starts with the corners, etc)
- Each tile type has a lambda for updating the current set based on the last tile placed (gargoyle was placed in a corner, remove it from the lich's set of available places)
From here it is very simple! Find the tile with the fewest possible spaces they can spawn in (spoilers, it's the dragon first), pick a random tile from that set, place it onto the board, and then communicate that that tile type was placed at that position to the remaining tiles so they can update their availability sets.
Next comes the lich who only has 4 places it can spawn, then likely the slime mage who is running shorter on edge pieces, etc. A gargoyle getting placed will communicate to its partner that it's availability has reduced to just 1-2 spots (either side) which shoots it up to spawn next, and so on and so forth:
The only tricky bit from all this is backtracking. Inevitably, you will have randomly painted yourself into a corner and your most-constrained next tile will have 0 possibilities.
The board being trivially copy-able helps here because I simply stored a copy of the board at every step! If I encounter a tile with 0 possibilities I can now:
- Roll back the previous tile decision
- Remove the decided position from that tile's possibilities
- Re-roll for a new position and continue!
- If I rewound and removed the last possibility for that tile, well, just recurse backward again!
Putting it Together
The algorithm for the board is now:
- Create a list of tiles, each using their type to create an initial set of possible positions
- Find the tile with the fewest possible spaces
- If the tile has 0 possibilities: a. rewind the board to the previous decision b. remove that decision from that tile's possibilities c. if 0 possibilities, go to a
- Select a random tile from the possible set and place the tile
- Send the placed tile type and position to the remaining tiles so they update their possible sets
- If there are remaining unplaced tiles, go to 2
Building for the Web
After playing with the UI and board generation, what I really wish I had from Dragonsweeper is a way to play it in bed on my phone! The original game ran in landscape mode and wasn't very playable on touch screen. This sent me down a long windy road of trying to get the game running in Emscripten
A few things made this achievable:
- The Chronicles Engine uses very few 3rd-party libraries, and virtually none outside of ImGui and SDL2
- The rendering is all software-side, with one simple OpenGL call to output the final EGA-like framebuffer
I had been using zig for building my game on other platforms and that is where I started, but I hit a brick wall of lacking documentation or examples to make it happen. I like my cross-compiling zig build but trying to get it to do emscripten was a bit maddening. There's an empscripten visual studio plugin, but I was having trouble getting it to do anything useful as well.
In the end, perhaps out of frustration, I employed the Mighty Makefile!
CXX = em++
CC = emcc
all: $(TARGET)
$(TARGET): $(OBJS) $(MAKEFILE_DEP)
@mkdir -p $(@D)
cp $(DEPLOY_FILES) $(BIN_DIR)
$(CXX) $(COMMON_FLAGS) $(LINK_FLAGS) $(OBJS) --shell-file em_files/em_shell.html -o $@ --embed-file em_deploy@assets
It was an interesting project! I had to learn very quickly a lot of web tech things that I only had passing knowledge of. One of the silly things was just SRGB being applied twice so everything was rendered dark.
It took a week or two of wrestling with, (suddenly being in 32bit was a particular struggle) but before I knew it I was just playing my engine, with my art, my sound effects, my music, running on my renderer, my waveform generation, it all worked!
I immediately threw it up on my personal site and linked it around and within the day there were other dragonsweeper fans sending me bug reports and suggestions, super fun! I think a web build of my game felt unattainable for me for a lot of different reasons, and was maybe one of the main reasons to use an off-the-shelf engine, but wow, the mighty wasm really just made that all happen.
Huge shoutouts to the folks working on Empscripten and SDL2/3 who make all of that stuff work!!!
Shortly after, the layout and resolution changed to be more portrait-mode-focused, a touch-based marking menu was added (sorely needed this in the original), and before I knew it I was building a simple python flask app to run a redis-backed leaderboard!
The best part about this project is that it paved the path forward to putting Chronicles proper on the web as well! Not long after shelving puzzle sweeper, I got the main game running and I've been able to use that to run some small friends playtests and is perfect for demos.
Setting it Aside
I had a lot of personal doubt with the project that I struggled with throughout. Regardless of attribution, or filling a specific unmet niche for platform and playability, I still felt pretty weird about pushing out “the mobile clone” of a currently-popular thing.
It was still very much inside the launch window of that game's popularity and receiving updates, so regardless of my intent, it felt wrong to potentially capture any of that energy.
In the end, the thing the port really needed was new art, new characters, and a bunch more UI work. There are graphical tells on the monsters that give information about how the board works and so not having those felt like there wasn't much point in releasing wider, particularly to anybody not familiar with v1.
So I set the game aside and took a break, going on to spend more of the year focused on the main game. It wasn't until early December that I felt inspired to pick it back up and put in the last 3-4 days necessary to polish it up for launch. By that point, it had been nearly a year and so I felt a lot more comfortable with saying “this is a remake of this other great game, here's what I changed and why, I hope you enjoy!”
Launching on Itch
This was an interesting experience for sure! The game spread fairly quickly (or as fast as I've seen from any of my stuff) on Bluesky and Mastodon. It was very fun to surprise old testers of the original version from earlier in the year 😄
24 hours later, the game had reached 1000 Browser Plays! It was exhilarating to watch people get into it, both old dragonsweeper fans and new people who hadn't played the original. I think my favorite comment was someone saying “Oh it's just a remake of dragonsweeper, even better!” as though I needed anything clearer to silence the aforementioned impostor concerns.
I was just so happy to see people understand the vision for it and enjoy it. Laura Michet blogged about playing it through her holiday travel day and just being able to provide that specific thing to someone really filled my heart with joy.
Itch discoverability of course seems very opaque and strange, but it was wild to see the game bubble around the various New & Popular lists for a few days.
About 5 days in, the game started appearing under the “Fresh Games” section of the main site and that is when visits from itch.io really started to surpass the others and impressions hit all-time highs. At some point there wasn't much of anything I could about it anymore, it was out of my hands, and I could just refresh the analytics page like watching an ant farm to see what happens.
3 weeks in, the game still sees over 100 daily browser plays (5000 and counting!) and that's just incredible to me. Recently a community of people from Brazil have gotten extremely into it and made the time leaderboards extremely competitive!
I've received so many kind and wonderful comments and messages from people who enjoy to game or inflicted their families with it, it has been such a wonderful, joyous experience and I'm so happy to have pushed through and gotten the work out there.
What's To Come
I've returned to work on Chronicles, so look forward to new updates there, but I am keeping an eye on Puzzle Sweeper! I have a lot of thoughts about what an update to that game might look like, maybe if it hits some arbitrarily exciting browser plays total I might start to tease something 👀
Thanks for Reading!
I'm kicking myself thinking of a handful of other things I wanted to cover but I think this is long enough for now. Thank you all so much for your support and I hope you have a wonderful day!~
 Wishlist Chronicles IV: Ebonheim!
Wishlist Chronicles IV: Ebonheim!
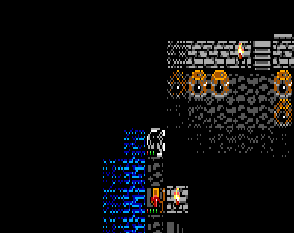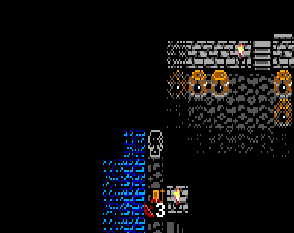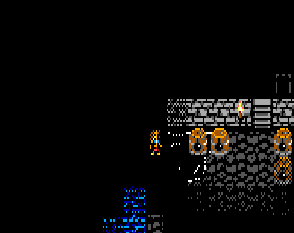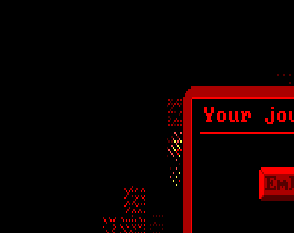
 Or: The Least Critical-Path Feature I Could Have Possibly Spent a Day On
Or: The Least Critical-Path Feature I Could Have Possibly Spent a Day On

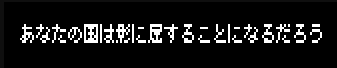
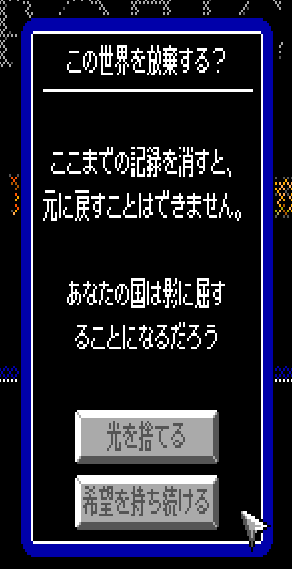
 The fruits of all of my labor with regard to asset editors and combat actions results in it being fairly trivial to add huge numbers of different types of abilities. It feels really good to just pop open the engine, write no code, and throw together a few systems into a new ability.
The fruits of all of my labor with regard to asset editors and combat actions results in it being fairly trivial to add huge numbers of different types of abilities. It feels really good to just pop open the engine, write no code, and throw together a few systems into a new ability. I've been having a time getting doors into the game over the last few weeks. After a failed attempt with the wrong methodology and several refactors I think I have it in a good place now!
I've been having a time getting doors into the game over the last few weeks. After a failed attempt with the wrong methodology and several refactors I think I have it in a good place now!